Introduction
Modern IT systems are no longer simple. Today, companies run applications across cloud platforms, containers, microservices, databases, APIs, security tools, monitoring dashboards, and automation pipelines. Every service produces logs, metrics, traces, alerts, and events. For DevOps engineers, SRE teams, cloud engineers, and IT operations teams, managing this complexity manually is becoming harder every day.
This is where AIOps becomes important.
AIOps helps IT teams use artificial intelligence, machine learning, automation, observability, and monitoring data to improve operations. Instead of depending only on manual checks and rule-based alerts, AIOps helps teams detect unusual behavior, reduce alert noise, find root causes faster, and automate common incident responses.
For DevOps engineers and SRE teams, AIOps is not just another tool category. It is becoming a practical skill for modern IT operations. Teams that understand AIOps can handle incidents faster, improve reliability, reduce downtime, and make better decisions using data.
This guide explains AIOps in simple English and gives a clear learning roadmap for beginners, DevOps professionals, SREs, cloud engineers, freshers, and managers who want to build a strong foundation in AI-driven IT operations.
What is AIOps?
AIOps stands for Artificial Intelligence for IT Operations.
In simple words, AIOps means using AI, machine learning, data analysis, automation, and monitoring information to improve IT operations. It helps teams understand what is happening inside complex systems and respond faster when something goes wrong.
AIOps collects data from different sources such as:
- Application logs
- Server metrics
- Cloud monitoring tools
- Network events
- Security alerts
- Traces from distributed systems
- Incident management tools
- CI/CD pipelines
- Infrastructure automation systems
After collecting the data, AIOps tools analyze patterns, detect anomalies, connect related events, and recommend or trigger actions.
For example, instead of showing 500 separate alerts during an outage, an AIOps system can group related alerts and show the most likely root cause. This saves time and helps engineers focus on solving the real problem.
AIOps combines several areas:
- Artificial intelligence
- Machine learning
- Observability
- Monitoring
- IT automation
- Incident management
- DevOps automation
- Cloud operations
- Service reliability engineering
The main goal of AIOps is not to replace engineers. The goal is to help engineers work smarter, respond faster, and manage large IT systems with more confidence.
Why AIOps Matters for Modern IT Teams
Modern IT teams face many operational challenges. Applications are distributed, infrastructure changes frequently, and customer expectations are high. Even a small delay or outage can affect business revenue and user trust.
AIOps matters because it helps teams manage these challenges in a more intelligent way.
Alert Noise Reduction
One of the biggest problems in IT operations is alert noise. Monitoring tools may generate hundreds or thousands of alerts, but not all alerts are useful.
AIOps can group related alerts, remove duplicates, and highlight the most important issues. This helps DevOps engineers and SREs avoid alert fatigue.
Faster Incident Detection
Traditional monitoring often depends on fixed thresholds. For example, an alert may trigger when CPU usage crosses 90%. But modern systems are more complex than that.
AIOps can detect unusual patterns even before a fixed threshold is crossed. This helps teams identify problems early.
Root Cause Analysis
During an incident, engineers often spend a lot of time checking dashboards, logs, metrics, and recent changes. AIOps can connect data from different sources and suggest possible root causes.
For example, it may show that an increase in errors started shortly after a new deployment or configuration change.
Predictive Monitoring
AIOps can study past data and identify future risks. It can predict capacity issues, traffic spikes, service degradation, or infrastructure problems.
This helps teams take action before users are affected.
Auto-Remediation
Auto-remediation means automatically fixing known problems using predefined workflows.
For example:
- Restarting a failed service
- Scaling cloud resources
- Clearing temporary files
- Rolling back a failed deployment
- Restarting a container
- Triggering a runbook
AIOps can help decide when these actions should be started.
Better Reliability
For SRE teams, reliability is a core goal. AIOps supports reliability by improving monitoring, reducing mean time to detect, reducing mean time to resolve, and helping teams learn from incidents.
AIOps vs MLOps
AIOps and MLOps are related, but they are not the same.
AIOps focuses on improving IT operations using AI and automation. MLOps focuses on building, deploying, monitoring, and managing machine learning models.
Both are important in modern technology teams, and many companies use both together.
| Point | AIOps | MLOps |
|---|---|---|
| Main focus | IT operations and reliability | Machine learning model lifecycle |
| Primary users | DevOps engineers, SREs, IT operations teams, cloud teams | Data scientists, ML engineers, MLOps engineers |
| Main goal | Detect incidents, reduce alerts, automate operations | Build, deploy, monitor, and improve ML models |
| Data used | Logs, metrics, traces, alerts, events, incidents | Datasets, features, models, predictions, experiments |
| Common tools | Monitoring, observability, alerting, automation, incident tools | Model registry, ML pipelines, experiment tracking, model monitoring |
| Example use case | Detect service outage and trigger remediation | Deploy a fraud detection model into production |
In simple terms, AIOps helps run IT systems better, while MLOps helps run machine learning systems better.
However, AIOps and MLOps can work together. For example, AIOps platforms may use machine learning models to detect anomalies, and those models may need MLOps practices for training, deployment, monitoring, and improvement.
Core Skills Needed to Learn AIOps
Before learning AIOps tools, beginners should build strong basics. AIOps is not only about using a platform. It requires understanding how IT systems work.
Monitoring and Observability
Monitoring helps teams know whether systems are working properly. Observability helps teams understand why something is happening.
Important concepts include:
- Logs
- Metrics
- Traces
- Dashboards
- Alerts
- Service health
- Error rates
- Latency
- Throughput
AIOps depends heavily on observability data.
Log Analysis
Logs are one of the most important sources of operational data. They help engineers understand application behavior, failures, errors, and user activity.
A beginner should learn how to:
- Search logs
- Filter logs
- Identify patterns
- Understand error messages
- Connect logs with incidents
Metrics and Traces
Metrics show numerical values such as CPU usage, memory usage, request count, error rate, and response time.
Traces help track a request across multiple services. They are very useful in microservices environments.
AIOps tools use both metrics and traces to detect problems and find root causes.
Incident Management
AIOps is closely connected with incident management. Engineers should understand:
- Incident lifecycle
- Severity levels
- On-call process
- Escalation
- Runbooks
- Post-incident review
- Mean time to detect
- Mean time to resolve
Cloud Basics
Many modern systems run on cloud platforms. AIOps learners should understand basic cloud concepts such as:
- Virtual machines
- Containers
- Kubernetes
- Load balancers
- Auto scaling
- Cloud monitoring
- Storage
- Networking
- Identity and access management
Python Basics
Python is useful for automation, data analysis, scripting, and machine learning. AIOps beginners do not need to become advanced Python developers immediately, but they should understand the basics.
Useful Python skills include:
- Reading files
- Working with APIs
- Processing logs
- Using libraries
- Writing automation scripts
- Basic data analysis
Machine Learning Fundamentals
AIOps uses machine learning for pattern detection, anomaly detection, prediction, and classification.
Important beginner topics include:
- Supervised learning
- Unsupervised learning
- Classification
- Clustering
- Time-series analysis
- Anomaly detection
- Model accuracy
- Training data
- False positives and false negatives
DevOps and Automation
AIOps works best when teams already understand DevOps and automation practices.
Important skills include:
- CI/CD pipelines
- Infrastructure as code
- Configuration management
- Scripting
- Containerization
- Release automation
- Monitoring automation
- Runbook automation
Popular AIOps Use Cases
AIOps can be used in many areas of IT operations. Below are some common use cases.
Anomaly Detection
Anomaly detection means finding unusual behavior in systems.
For example:
- Sudden increase in error rate
- Unexpected traffic drop
- High memory usage
- Slow API response
- Unusual login activity
- Database query delay
AIOps can detect these problems automatically by learning normal behavior.
Event Correlation
In a complex system, one problem may create many alerts. Event correlation connects related alerts and shows them as one incident.
For example, if a database becomes slow, it may trigger alerts from the application, API gateway, backend service, and customer dashboard. AIOps can connect these alerts and show the database as the possible root cause.
Intelligent Alerting
Traditional alerts are often based on fixed rules. Intelligent alerting uses context, patterns, and historical data to reduce unnecessary alerts.
This helps teams focus on real issues.
Capacity Prediction
AIOps can help predict when systems may need more resources. It can analyze usage trends and suggest when to scale servers, storage, or cloud resources.
This is useful for cloud planning and cost control.
Self-Healing Infrastructure
Self-healing infrastructure means systems can automatically recover from known issues.
Examples include:
- Restarting unhealthy containers
- Replacing failed nodes
- Scaling services during traffic spikes
- Running automation scripts
- Clearing disk space
AIOps can support self-healing by detecting issues and triggering automated workflows.
Incident Automation
AIOps can reduce manual work during incidents by automatically collecting logs, opening tickets, notifying teams, and running basic checks.
This improves response time.
Cloud Cost Visibility
AIOps can also help identify unusual cloud usage patterns. For example, it can detect sudden increases in resource consumption or unused infrastructure.
This helps cloud teams control costs.
Service Reliability Improvement
AIOps helps SRE teams improve reliability by identifying repeated incidents, weak services, noisy alerts, and risky changes.
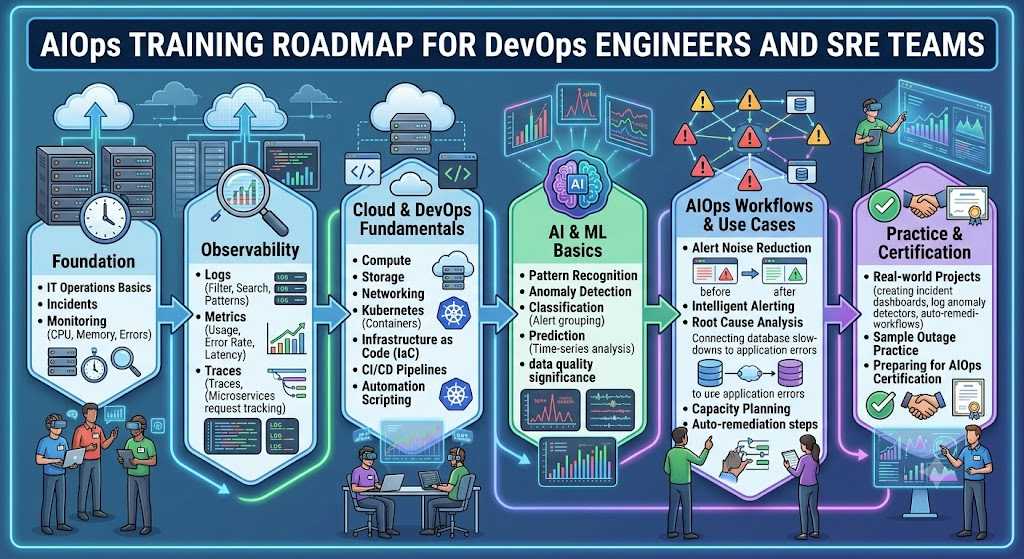
AIOps Learning Roadmap for Beginners
Learning AIOps becomes easier when you follow a structured roadmap. Below is a practical step-by-step path.
Step 1: Learn IT Operations Basics
Start with the basics of IT operations. Understand how applications, servers, databases, networks, and cloud systems work together.
Learn common operational problems such as:
- Downtime
- Slow performance
- Deployment failures
- Configuration issues
- Resource exhaustion
- Security alerts
- Network latency
This foundation will help you understand why AIOps is needed.
Step 2: Understand Monitoring and Observability
Next, learn how monitoring and observability work.
Focus on:
- Logs
- Metrics
- Traces
- Dashboards
- Alerts
- Error tracking
- Service-level indicators
- Service-level objectives
Without observability basics, AIOps tools may feel confusing.
Step 3: Learn DevOps and Cloud Fundamentals
AIOps is closely connected to DevOps and cloud operations. Learn basic DevOps workflows such as CI/CD, automation, containers, and infrastructure as code.
Also learn cloud basics such as compute, storage, networking, Kubernetes, and cloud monitoring.
Step 4: Learn AI and ML Basics
You do not need to become a data scientist to start learning AIOps, but you should understand basic machine learning ideas.
Focus on:
- What machine learning means
- How models learn patterns
- What anomaly detection is
- What prediction means
- Why data quality matters
- Why human review is still important
This will help you understand how AIOps platforms make decisions.
Step 5: Practice AIOps Tools and Workflows
After learning the basics, start practicing with AIOps tools and workflows.
Practice tasks like:
- Collecting logs
- Creating dashboards
- Setting alerts
- Detecting anomalies
- Correlating events
- Creating incident workflows
- Running automation scripts
- Connecting monitoring tools with ticketing tools
Do not focus only on tool buttons. Focus on the workflow and the problem being solved.
Step 6: Work on Real Projects
Real projects build confidence. Start with small projects and increase complexity slowly.
For example, create a simple monitoring pipeline, detect unusual log patterns, or build a basic alert classification system.
Projects help you understand real-world issues better than theory alone.
Step 7: Prepare for AIOps Certification
Once you understand concepts and have some hands-on practice, you can prepare for an AIOps certification.
AIOps certification can help learners validate their knowledge, build confidence, and show structured learning. However, certification should support practical skills, not replace them.
Real-World AIOps Project Ideas
Practical projects are very important for learning AIOps. Here are some useful project ideas.
Alert Classification System
Build a system that classifies alerts into categories such as critical, warning, informational, duplicate, or false positive.
This helps understand alert noise reduction.
Log Anomaly Detector
Create a simple log analysis project that detects unusual error messages or sudden changes in log volume.
This helps build basic anomaly detection skills.
Incident Prediction Dashboard
Build a dashboard that uses metrics such as CPU, memory, latency, and error rate to identify possible upcoming incidents.
This helps understand predictive monitoring.
Auto-Remediation Workflow
Create a workflow that automatically restarts a failed service or sends a notification when a known issue occurs.
This helps understand incident automation.
Cloud Monitoring Pipeline
Build a pipeline that collects cloud metrics, creates alerts, and shows system health in a dashboard.
This helps connect cloud operations with AIOps concepts.
Who Should Learn AIOps?
AIOps is useful for many roles in modern IT.
DevOps Engineers
DevOps engineers can use AIOps to improve automation, monitoring, CI/CD reliability, and incident response.
SREs
SRE teams can use AIOps to improve service reliability, reduce incident response time, and manage large-scale systems.
Cloud Engineers
Cloud engineers can use AIOps for cloud monitoring, capacity planning, cost visibility, and infrastructure automation.
IT Operations Teams
IT operations teams can use AIOps to reduce manual work, manage alerts, and improve system availability.
Monitoring Engineers
Monitoring engineers can use AIOps to build smarter dashboards, alerts, and event correlation workflows.
Managers
Managers can learn AIOps to understand how AI-driven IT operations can improve team productivity, reliability, and operational decision-making.
Freshers
Freshers who want to build a modern IT career can learn AIOps along with DevOps, cloud, automation, and observability.
Common Mistakes Beginners Make
Learning AIOps becomes easier when you avoid common mistakes.
Learning Tools Without Concepts
Many beginners start directly with tools. This creates confusion because they do not understand the problem the tool is solving.
First learn observability, monitoring, incidents, and automation. Then learn tools.
Ignoring Observability Basics
AIOps depends on good data. If logs, metrics, and traces are poor, AIOps results will also be poor.
Strong observability is the foundation of successful AIOps.
Depending Only on AI Without Human Review
AI can help, but it is not always perfect. Human review is important, especially for critical systems.
AIOps should support engineers, not blindly replace judgment.
Not Practicing Real Incidents
Reading about incidents is useful, but practicing real workflows is better. Beginners should work on sample incidents, failure scenarios, and troubleshooting exercises.
Skipping Automation Fundamentals
AIOps often triggers automation. If you do not understand scripting, runbooks, APIs, and workflows, auto-remediation will be difficult to implement safely.
AIOps Career Opportunities
AIOps is creating new opportunities for IT professionals who understand operations, automation, cloud, observability, and AI basics.
AIOps Engineer
An AIOps Engineer works on monitoring data, anomaly detection, event correlation, incident automation, and AIOps platform implementation.
MLOps Engineer
An MLOps Engineer focuses on managing machine learning pipelines, model deployment, model monitoring, and production ML systems.
Site Reliability Engineer
SREs use AIOps to improve system reliability, reduce incident response time, and manage service-level objectives.
Platform Engineer
Platform Engineers can use AIOps to improve internal developer platforms, infrastructure visibility, and automation workflows.
Cloud Automation Engineer
Cloud Automation Engineers can use AIOps for cloud monitoring, scaling, cost visibility, and automated remediation.
Observability Engineer
Observability Engineers can use AIOps to improve logs, metrics, traces, dashboards, alerts, and root cause analysis.
AIOps Training Plan for DevOps Engineers and SRE Teams
A practical AIOps training plan should include concepts, tools, projects, and real incident workflows.
| Phase | What to Learn | Practice Activity |
|---|---|---|
| Foundation | IT operations, incidents, monitoring basics | Study sample outage scenarios |
| Observability | Logs, metrics, traces, dashboards | Build a basic service dashboard |
| DevOps | CI/CD, automation, infrastructure as code | Automate a simple deployment check |
| AI/ML Basics | Anomaly detection, prediction, classification | Detect unusual log patterns |
| AIOps Workflows | Alert correlation, root cause analysis, intelligent alerting | Group related alerts from sample data |
| Automation | Runbooks, scripts, APIs, remediation | Create a restart or notification workflow |
| Project Stage | Real-world AIOps use cases | Build an incident prediction dashboard |
| Certification Stage | Structured learning and assessment | Prepare for AIOps certification |
This roadmap is useful for both individual learners and teams planning internal AIOps training.
FAQs
1. What is AIOps in simple words?
AIOps means using artificial intelligence, machine learning, monitoring data, and automation to improve IT operations. It helps teams detect problems, reduce alerts, find root causes, and respond faster.
2. Is AIOps only for large companies?
No. Large companies need AIOps because they manage complex systems, but small and medium teams can also benefit from better monitoring, alerting, and automation.
3. Do I need machine learning knowledge to learn AIOps?
Basic machine learning knowledge is helpful, but you do not need to become a data scientist. Start with concepts like anomaly detection, prediction, classification, and data quality.
4. Is AIOps useful for DevOps engineers?
Yes. DevOps engineers can use AIOps to improve monitoring, incident response, deployment reliability, automation, and cloud operations.
5. How is AIOps useful for SRE teams?
SRE teams can use AIOps to reduce alert noise, detect incidents faster, improve root cause analysis, and support service reliability goals.
6. What are the main skills needed for AIOps?
Important skills include monitoring, observability, log analysis, incident management, cloud basics, DevOps automation, Python basics, and machine learning fundamentals.
7. What is the difference between AIOps and MLOps?
AIOps focuses on IT operations and reliability. MLOps focuses on building, deploying, and managing machine learning models in production.
8. Can AIOps fully automate incident management?
AIOps can automate many repeated tasks, but human review is still important for complex and critical incidents. Safe automation should be planned carefully.
9. What are good beginner projects for AIOps?
Good beginner projects include alert classification, log anomaly detection, incident dashboards, auto-remediation workflows, and cloud monitoring pipelines.
10. Is AIOps certification useful?
AIOps certification can be useful when it is combined with practical learning. It helps validate knowledge, but real projects and hands-on practice are equally important.
Conclusion
AIOps is becoming an important skill for modern IT teams because systems are becoming more complex, alerts are increasing, and businesses need faster incident response. DevOps engineers, SREs, cloud engineers, monitoring teams, and IT operations professionals can use AIOps to improve reliability, automation, and decision-making.
The best way to learn AIOps is to start with strong fundamentals. Learn monitoring, observability, logs, metrics, traces, incidents, cloud basics, DevOps automation, and machine learning concepts. After that, practice real workflows and build practical projects.
AIOps is not only about using AI tools. It is about understanding IT operations deeply and using intelligent automation to solve real problems. For anyone building a future-ready career in DevOps, SRE, cloud, or IT automation, AIOps is a valuable skill to learn.